Hi there.
Recently I was sitting in a bad place again. I had to automate one process step in a workflow, which was entirely based on processing files of different type, layout and size.
I love automating things by developing software, but I hate doing so whenever it is based entirely on file systems.
To make matters worse, I had to process Excel files ... again! Being a very experienced VBA programmer, in which I do take shame, not pride, I knew it will give me trouble.
Since I do not want to code in VBA anymore, I decided to use Java and the Apache POI API.
Started to use the API and was happy. See the following articles for reference.
How to setup an eclipse project to use POI.
Identifying the last row in Excel files can be hard. Depends on what you define as last row ;0).
A high level wrapper class around POI for processing Excel files.
And here the problem ...
Soon, of course, I ran into problems. I has to process a file, which was over 10 MB big and ran into following exception during unit testing.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
java.lang.OutOfMemoryError: GC overhead limit exceeded
at org.apache.poi.xssf.usermodel.XSSFCell.getRichStringCellValue(XSSFCell.java:299)
at org.apache.poi.xssf.usermodel.XSSFCell.getStringCellValue(XSSFCell.java:262)
at de.consulting.bolte.io.file.ExcelFile.getNextRow(ExcelFile.java:248)
at de.consulting.bolte.db.ft.ViolationReader.nextViolation(ViolationReader.java:64)
at de.consulting.bolte.db.ft.ViolationReader.readSourceFile(ViolationReader.java:46)
at de.consulting.bolte.db.test.TestViolationReader.testReadBigSourceFile(TestViolationReader.java:57)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:606)
at org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:47)
at org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
at org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:44)
at org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
at org.junit.internal.runners.statements.RunBefores.evaluate(RunBefores.java:26)
at org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
at org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:271)
at org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:70)
at org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:50)
at org.junit.runners.ParentRunner$3.run(ParentRunner.java:238)
at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:63)
at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:236)
at org.junit.runners.ParentRunner.access$000(ParentRunner.java:53)
at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:229)
at org.junit.runners.ParentRunner.run(ParentRunner.java:309)
at org.eclipse.jdt.internal.junit4.runner.JUnit4TestReference.run(JUnit4TestReference.java:50)
at org.eclipse.jdt.internal.junit.runner.TestExecution.run(TestExecution.java:38)
at org.eclipse.jdt.internal.junit.runner.RemoteTestRunner.runTests(RemoteTestRunner.java:459)
at org.eclipse.jdt.internal.junit.runner.RemoteTestRunner.runTests(RemoteTestRunner.java:675)
at org.eclipse.jdt.internal.junit.runner.RemoteTestRunner.run(RemoteTestRunner.java:382)
at org.eclipse.jdt.internal.junit.runner.RemoteTestRunner.main(RemoteTestRunner.java:192)
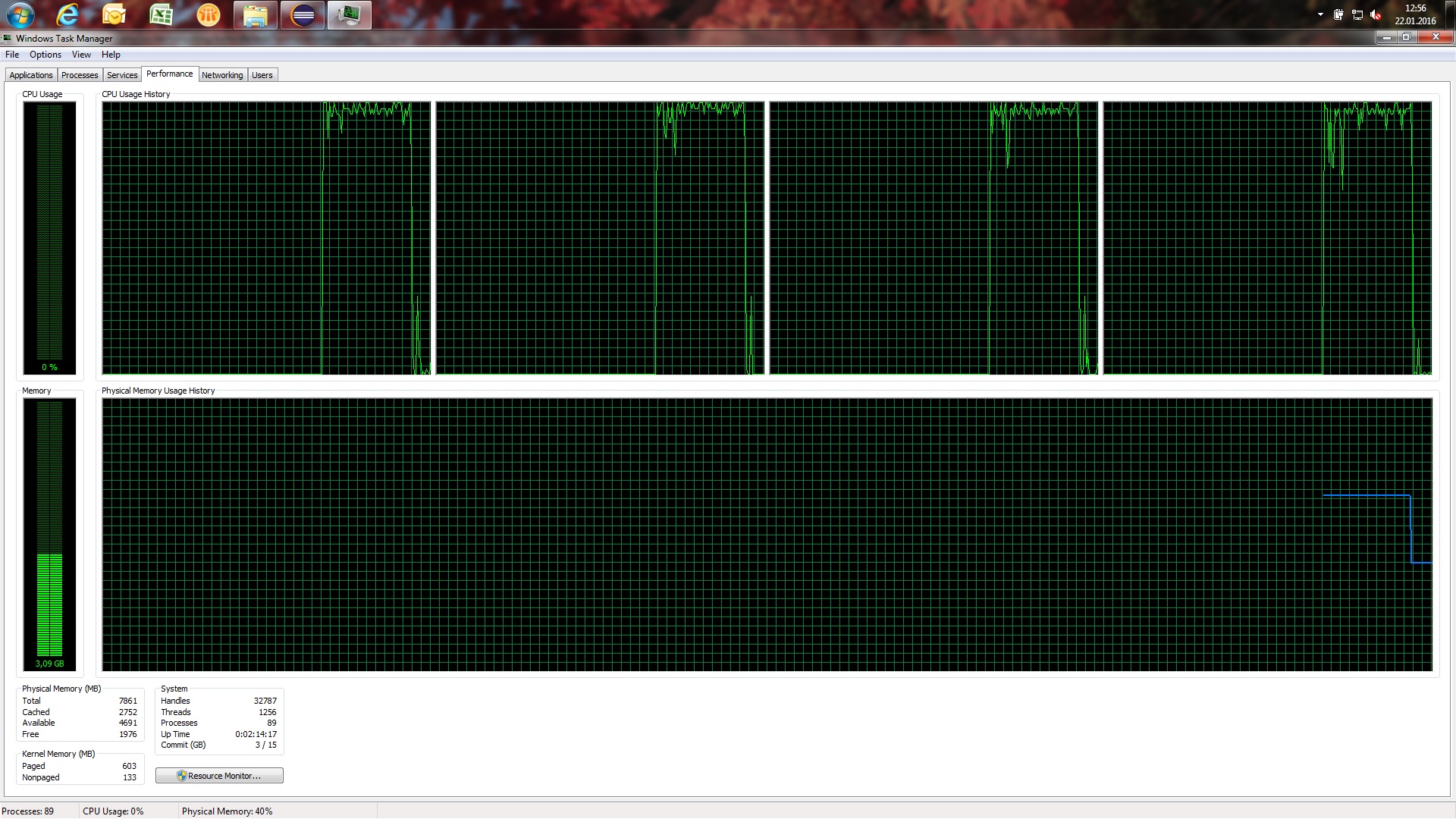
Root cause is obvious: out of memory caused by reading a Row in a Sheet using POI API.
Below you can see the performance of my machine and how it aborts after some time dropping from 5 GB RAM usage and 100% CPU usage. Not satisfying.
Event API - a solution for "intermediate developers"
Google research delivered the following interesting article provided by Apache on the POI Event API, which apparently has to be used instead of the user API for very big Excel files. Having this said, the people I worked with see Excel files as "big" when they are above 50 MB. Excel driven companies (hate them because it takes a lot of pain to change for the better and love them because there is always work).
http://poi.apache.org/spreadsheet/how-to.html#event_api
Search for the heading "XSSF and SAX (Event API)".
The event API is separated into different parts for different Excel file types. For reading big Excel files in xlsx format introduced with Excel 2007 you can use the XSSF and SAX (Event API). Basically you will parse the underlying XML and won't rely on the POI usermodel API anymore. Therefore you could theoretically develop your own API for parsing xlsx files, but I do not recommend doing so. If you however want to take this step JAXB might be of interest for you. I will definitely not go this far.
Starting out with simple unit tests provided by Apache under above URL for the event API, I ran into different exceptions.
First try I got the file path to my source file I wanted to read wrong. This gave me following exception, which is not very helpful. I would have liked a FileNotFoundException.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
java.lang.IllegalStateException: Zip File is closed
at org.apache.poi.openxml4j.util.ZipFileZipEntrySource.getEntries(ZipFileZipEntrySource.java:45)
at org.apache.poi.openxml4j.opc.ZipPackage.getPartsImpl(ZipPackage.java:184)
at org.apache.poi.openxml4j.opc.OPCPackage.getParts(OPCPackage.java:684)
at org.apache.poi.openxml4j.opc.OPCPackage.open(OPCPackage.java:227)
at org.apache.poi.openxml4j.opc.OPCPackage.open(OPCPackage.java:187)
at de.consulting.bolte.test.ExcelFileTest.testReadBigExcelFile(ExcelFileTest.java:246)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(Unknown Source)
at java.lang.reflect.Method.invoke(Unknown Source)
at org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:47)
at org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
at org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:44)
at org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
at org.junit.internal.runners.statements.RunBefores.evaluate(RunBefores.java:26)
at org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
at org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:271)
at org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:70)
at org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:50)
at org.junit.runners.ParentRunner$3.run(ParentRunner.java:238)
at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:63)
at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:236)
at org.junit.runners.ParentRunner.access$000(ParentRunner.java:53)
at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:229)
at org.junit.runners.ParentRunner.run(ParentRunner.java:309)
at org.eclipse.jdt.internal.junit4.runner.JUnit4TestReference.run(JUnit4TestReference.java:50)
at org.eclipse.jdt.internal.junit.runner.TestExecution.run(TestExecution.java:38)
at org.eclipse.jdt.internal.junit.runner.RemoteTestRunner.runTests(RemoteTestRunner.java:459)
at org.eclipse.jdt.internal.junit.runner.RemoteTestRunner.runTests(RemoteTestRunner.java:675)
at org.eclipse.jdt.internal.junit.runner.RemoteTestRunner.run(RemoteTestRunner.java:382)
at org.eclipse.jdt.internal.junit.runner.RemoteTestRunner.main(RemoteTestRunner.java:192)
Second try I got the file path correct, but then I ran into following exception.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
java.lang.ClassNotFoundException: org.apache.xerces.parsers.SAXParser
at org.xml.sax.helpers.XMLReaderFactory.loadClass(Unknown Source)
at org.xml.sax.helpers.XMLReaderFactory.createXMLReader(Unknown Source)
at de.consulting.bolte.test.ExcelFileTest.fetchSheetParser(ExcelFileTest.java:264)
at de.consulting.bolte.test.ExcelFileTest.testReadBigExcelFile(ExcelFileTest.java:250)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(Unknown Source)
at java.lang.reflect.Method.invoke(Unknown Source)
at org.junit.runners.model.FrameworkMethod$1.runReflectiveCall(FrameworkMethod.java:47)
at org.junit.internal.runners.model.ReflectiveCallable.run(ReflectiveCallable.java:12)
at org.junit.runners.model.FrameworkMethod.invokeExplosively(FrameworkMethod.java:44)
at org.junit.internal.runners.statements.InvokeMethod.evaluate(InvokeMethod.java:17)
at org.junit.internal.runners.statements.RunBefores.evaluate(RunBefores.java:26)
at org.junit.internal.runners.statements.RunAfters.evaluate(RunAfters.java:27)
at org.junit.runners.ParentRunner.runLeaf(ParentRunner.java:271)
at org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:70)
at org.junit.runners.BlockJUnit4ClassRunner.runChild(BlockJUnit4ClassRunner.java:50)
at org.junit.runners.ParentRunner$3.run(ParentRunner.java:238)
at org.junit.runners.ParentRunner$1.schedule(ParentRunner.java:63)
at org.junit.runners.ParentRunner.runChildren(ParentRunner.java:236)
at org.junit.runners.ParentRunner.access$000(ParentRunner.java:53)
at org.junit.runners.ParentRunner$2.evaluate(ParentRunner.java:229)
at org.junit.runners.ParentRunner.run(ParentRunner.java:309)
at org.eclipse.jdt.internal.junit4.runner.JUnit4TestReference.run(JUnit4TestReference.java:50)
at org.eclipse.jdt.internal.junit.runner.TestExecution.run(TestExecution.java:38)
at org.eclipse.jdt.internal.junit.runner.RemoteTestRunner.runTests(RemoteTestRunner.java:459)
at org.eclipse.jdt.internal.junit.runner.RemoteTestRunner.runTests(RemoteTestRunner.java:675)
at org.eclipse.jdt.internal.junit.runner.RemoteTestRunner.run(RemoteTestRunner.java:382)
at org.eclipse.jdt.internal.junit.runner.RemoteTestRunner.main(RemoteTestRunner.java:192)
Caused by: java.lang.ClassNotFoundException: org.apache.xerces.parsers.SAXParser
at java.net.URLClassLoader$1.run(Unknown Source)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(Unknown Source)
at java.lang.ClassLoader.loadClass(Unknown Source)
at sun.misc.Launcher$AppClassLoader.loadClass(Unknown Source)
at java.lang.ClassLoader.loadClass(Unknown Source)
at org.xml.sax.helpers.NewInstance.newInstance(Unknown Source)
... 29 more
Sigh! Anyhow. Removing the reference to the not existing class did the trick for me, but might not do the trick for you. The above exception is caused by the following call to method createXmlHandler(String className).
XMLReader parser = XMLReaderFactory.createXMLReader(
"org.apache.xerces.parsers.SAXParser"
);
My first best guess solution was to switch to the overridden method createXmlHandler(), which attempts to guess the XmlHandler by checking certain places for constants providing the class path for the XMLHandler to use. Just read the Java Doc for the method XMLReaderFactory.createXMLReader() and you understand what I mean.
So I changed the method to fetch the sheet parser to have the XMLReaderFactory determine the XMLReader class I need itself.
1
2
3
4
5
6
7
8
9
10
11
12
public XMLReader fetchSheetParser(SharedStringsTable sst)
throws SAXException {
/*
* XMLReader parser = XMLReaderFactory
* .createXMLReader("org.apache.xerces.parsers.SAXParser");
*/
XMLReader parser = XMLReaderFactory.createXMLReader();
ContentHandler handler = new SheetHandler(sst);
parser.setContentHandler(handler);
return parser;
}
Et volia. We have console output as you can see in below screenshot. The API processed over 91.405 records and 14 columns most of them filled (no null Rows in referenced Excel Sheet) in 45 seconds without exhausting my machines resources. I would say that POI passed my performance test and I am happy again.
Refactoring to my high level classes using POI
Now for understanding the source code provided by Apache and the new concept behind it. Below you can find the source code as it is working for me as Unit Test using JUnit4. An explanation of the source code can be found below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
/**
*
*/
package de.consulting.bolte.test;
import static org.junit.Assert.fail;
import java.io.IOException;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.HashMap;
import org.apache.poi.EncryptedDocumentException;
import org.apache.poi.openxml4j.exceptions.InvalidFormatException;
import org.apache.poi.openxml4j.exceptions.OpenXML4JException;
import org.apache.poi.openxml4j.opc.OPCPackage;
import org.apache.poi.xssf.eventusermodel.XSSFReader;
import org.apache.poi.xssf.model.SharedStringsTable;
import org.apache.poi.xssf.usermodel.XSSFRichTextString;
import org.junit.After;
import org.junit.Assert;
import org.junit.Before;
import org.junit.Test;
import org.xml.sax.Attributes;
import org.xml.sax.ContentHandler;
import org.xml.sax.InputSource;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.DefaultHandler;
import org.xml.sax.helpers.XMLReaderFactory;
/**
* @author Alexander Bolte (2016)
*
*/
public class ExcelFileTest {
/**
* @throws java.lang.Exception
*/
@Before
public void setUp() throws Exception {
}
/**
* @throws java.lang.Exception
*/
@After
public void tearDown() throws Exception {
}
/**
* @throws IOException
* @throws OpenXML4JException
* @throws SAXException
*/
@Test
public void testReadBigExcelFile() throws IOException, OpenXML4JException,
SAXException {
final String fileName = "./src/de/consulting/bolte/test/xlTestReadBigFile.xlsx";
/*
* Opens a package (archive / xlsx file) with read / write permissions.
* It is also possible to access it read only, which should be the first
* choice for read operations in case the file is already accessed by
* another user. To open read only provide an InputStream instead of a
* file path.
*/
OPCPackage pkg = OPCPackage.open(fileName);
XSSFReader r = new XSSFReader(pkg);
/*
* Read the sharedStrings.xml from an xlsx file into an object
* representation.
*/
SharedStringsTable sst = r.getSharedStringsTable();
/*
* Hand a read SharedStringsTable for further reference to the SAXParser
* and the underlying ContentHandler.
*/
XMLReader parser = fetchSheetParser(sst);
/*
* To look up the Sheet Name / Sheet Order / rID, you need to process
* the core Workbook stream. Normally it's of the form rId# or rSheet#
*
* Great! How do I know, if it is rSheet or rId? Thanks Microsoft.
* Anyhow, let's carry on with the noise.
*
* I reference the third sheet from the left since the index starts at
* one.
*/
InputStream sheet2 = r.getSheet("rId3");
InputSource sheetSource = new InputSource(sheet2);
/*
* Run through a Sheet using a window of several XML tags instead of
* attempting to read the whole file into RAM at once. Leaves the
* handling of file content to the ContentHandler, which is in this case
* the nested class SheetHandler.
*/
parser.parse(sheetSource);
/*
* Close the underlying InputStream for a Sheet XML.
*/
sheet2.close();
}
public XMLReader fetchSheetParser(SharedStringsTable sst)
throws SAXException {
/*
* XMLReader parser = XMLReaderFactory
* .createXMLReader("org.apache.xerces.parsers.SAXParser");
*/
XMLReader parser = XMLReaderFactory.createXMLReader();
ContentHandler handler = new SheetHandler(sst);
parser.setContentHandler(handler);
return parser;
}
/**
* Test method for
* {@link de.consulting.bolte.io.file.ExcelFile#addRow(java.util.HashMap)}.
*/
@Test
public void testAddRow() {
fail("Not yet implemented");
}
private static class SheetHandler extends DefaultHandler {
private SharedStringsTable sst;
private String lastContents;
private boolean nextIsString;
private SheetHandler(SharedStringsTable sst) {
this.sst = sst;
}
public void startElement(String uri, String localName, String name,
Attributes attributes) throws SAXException {
// c => cell
if (name.equals("c")) {
// Print the cell reference
System.out.print(attributes.getValue("r") + " - ");
// Figure out if the value is an index in the SST
String cellType = attributes.getValue("t");
if (cellType != null && cellType.equals("s")) {
nextIsString = true;
} else {
nextIsString = false;
}
}
// Clear contents cache
lastContents = "";
}
public void endElement(String uri, String localName, String name)
throws SAXException {
// Process the last contents as required.
// Do now, as characters() may be called more than once
if (nextIsString) {
int idx = Integer.parseInt(lastContents);
lastContents = new XSSFRichTextString(sst.getEntryAt(idx))
.toString();
nextIsString = false;
}
// v => contents of a cell
// Output after we've seen the string contents
if (name.equals("v")) {
System.out.println(lastContents);
}
}
public void characters(char[] ch, int start, int length)
throws SAXException {
lastContents += new String(ch, start, length);
}
}
}
So, in or der to understand what above code is doing, it helps to understand some of Excel file type internals. Lets assume the following screenshot as my sample file.
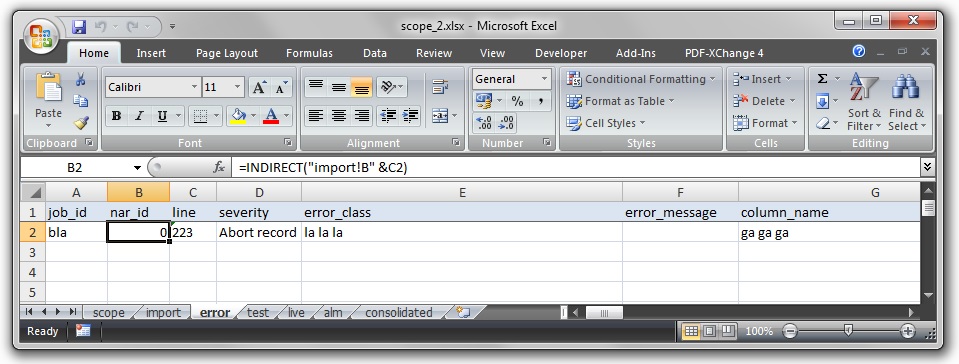
It has several worksheets and in the worksheet of interest only one row with data. If I open the same file with an archiving software like WinRAR I will see something like this.
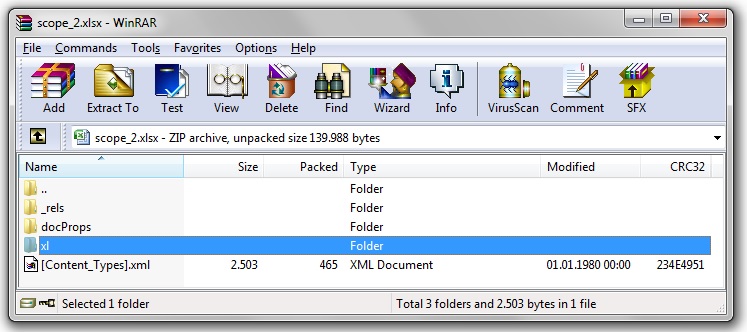
Open the directory "xl" and have a look at the files in the directory worksheets as well as the file "sharedStrings.xml".
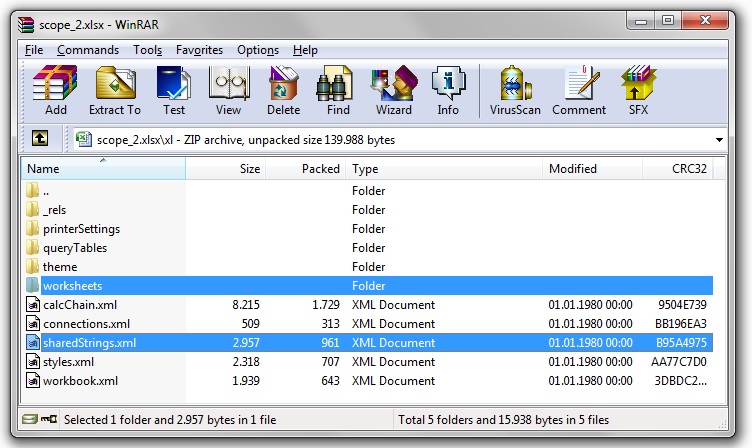
The concept behind the file "sharedStrings.xml" in order to save space is to save a String only once and hold only a reference to a position of an xml tag in the sharedStrings.xml instead of repeatedly saving the same value in one file. The directory worksheets contains several or only one XML file representing a Sheet in a Workbook. If you open one of the Sheet XML files, you will see that it does not contain any Strings in cells, but numbers. Pick a number of a cell you know the content of and check a tag at this position in the sharedStrings.xml. You will find the value that is displayed in the cell.
The SAXParser simply runs through a handed XML file representing a Sheet top to bottom. During this each XML tag is handed to a ContentHandler set for a current instantiation of a parser. The nested class SheetHandler is the ContentHandler for above unit test. If it finds a cell indicated by the tag name "c" it will check if the contained value is of type String. If it is a String, it will get the corresponding value from the SharedStringsTable handed to the handler at creation of a new instance and print the gotten value in the console.
Below a screenshot of an example sharedStrings.xml in Eclipse.
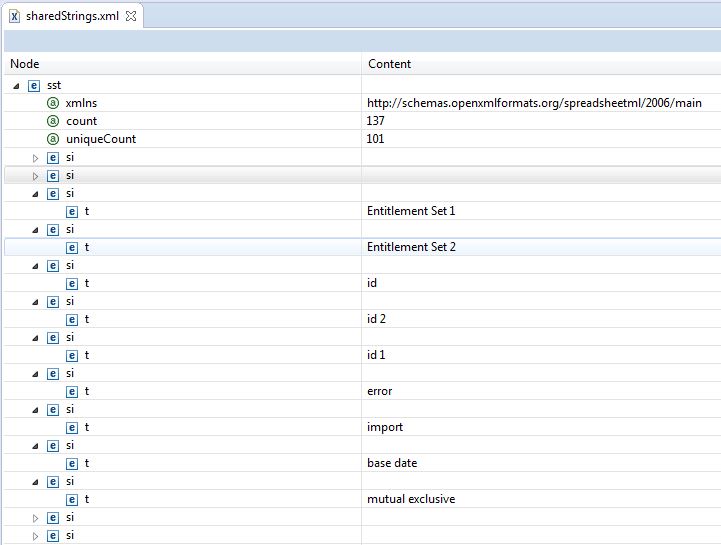
I will now have to adjust this to meet my requirements as I also want to handle values, which are not Strings. I will refactor my class ExcelFile to be able to decide itself when to use the event API and when to use the usermodel API or a mix of both.
POI usermodel and StAX vs. SAX
SAX and StAX are event based XML Streaming APIs, which means they deliver events to a Parser, which can then be interpreted. Event based because a Parser can ignore certain events and only "listen" to events, which are of interest. When reading Excel files using one of these APIs you will most likely not be interested in the formatting of an Excel sheet. Therefore your Parser will probably ignore everything except "rows" and cells ("c").
Tree based APIs like the POI usermodel or DOM are very inefficient when it comes to memory usage. They have to read the whole file into memory and the tree representation of XML files tends to be several times larger than the original file.
SAX and StAX are streaming APIs which differ in the way data is streamed. SAX is a push API, while StAX is pulling the information in chunks from a file. StAX above SAX leaves the utilizing program in control of when a next chunck of data is gotten. Using SAX you really have to implement a listener concept, since you do not have control over when data is pushed into your program.
Now, ... since we have to already use StAX or SAX to parse big Excel files, why would we still need POI? Above I briefly documented how an Excel file is set up internally. In order to handle special things like the shared strings table or the archive itself POI is still useful. Also you will most likely end up parsing single rows from a sheet into the POI usermodel because it provides a convenient API for handling Excel objects. However this is totally up to you and your use case. You could in general stream Excel files without POI just using StAX or SAX.
Reading Excel 2007 files with StAX
Since the following POI web page only provides an example for streaming an Excel file using SAX, I coded a unit test using StAX. Compared to SAX, StAX is it much more intuitive to code, read and debug. Enjoy.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
package de.consulting.bolte.test;
import static org.junit.Assert.fail;
import java.io.IOException;
import java.io.InputStream;
import java.util.ArrayList;
import java.util.HashMap;
import javax.xml.stream.XMLInputFactory;
import javax.xml.stream.XMLStreamConstants;
import javax.xml.stream.XMLStreamException;
import javax.xml.stream.XMLStreamReader;
import org.apache.poi.EncryptedDocumentException;
import org.apache.poi.openxml4j.exceptions.InvalidFormatException;
import org.apache.poi.openxml4j.exceptions.OpenXML4JException;
import org.apache.poi.openxml4j.opc.OPCPackage;
import org.apache.poi.xssf.eventusermodel.XSSFReader;
import org.apache.poi.xssf.model.SharedStringsTable;
import org.apache.poi.xssf.usermodel.XSSFRichTextString;
import org.junit.After;
import org.junit.Assert;
import org.junit.Before;
import org.junit.Test;
import org.xml.sax.Attributes;
import org.xml.sax.ContentHandler;
import org.xml.sax.InputSource;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.DefaultHandler;
import org.xml.sax.helpers.XMLReaderFactory;
import de.consulting.bolte.io.file.ExcelFile;
...
@Test
public void testStreamBigFile() throws IOException, OpenXML4JException,
XMLStreamException {
final String fileName = "./src/de/consulting/bolte/test/xlTestReadBigFile.xlsx";
final String ROW = "row";
final String CELL = "c";
final String CELL_TYPE = "t";
final String CELL_TYPE_STRING = "s";
/*
* Opens a package (archive / xlsx file) with read / write permissions.
* It is also possible to access it read only, which should be the first
* choice for read operations in case the file is already accessed by
* another user. To open read only provide an InputStream instead of a
* file path.
*/
OPCPackage pkg = OPCPackage.open(fileName);
XSSFReader r = new XSSFReader(pkg);
/*
* Read the sharedStrings.xml from an xlsx file into an object
* representation.
*/
SharedStringsTable sst = r.getSharedStringsTable();
/*
* To look up the Sheet Name / Sheet Order / rID, you need to process
* the core Workbook stream. Normally it's of the form rId# or rSheet#
*
* Great! How do I know, if it is rSheet or rId? Thanks Microsoft.
* Anyhow, let's carry on with the noise.
*
* I reference the third sheet from the left since the index starts at
* one.
*/
InputStream sheet2 = r.getSheet("rId3");
/*
* Get a parser for a Sheet.
*/
XMLInputFactory fac = XMLInputFactory.newInstance();
XMLStreamReader parser = fac.createXMLStreamReader(sheet2);
String cellType = "";
while (parser.hasNext()) {
int eventType = parser.next();
if (eventType == XMLStreamConstants.START_ELEMENT) {
if (parser.getLocalName().equals(ROW)) {
System.out.println();
System.out.print("row : " + parser.getAttributeValue(0));
} else if (parser.getLocalName().equals(CELL)) {
System.out.print(" | " + parser.getAttributeValue(0));
/*
* The following call to method getAttributeValue is too
* slow as expected. In addition it gives the full namespace
* concatenated with the value of an attribute
*/
// cellType = parser.getAttributeValue(null, CELL_TYPE);
cellType = parser.getAttributeValue(2);
}
} else if (eventType == XMLStreamConstants.CDATA
| eventType == XMLStreamConstants.CHARACTERS) {
if (cellType != null && cellType.equals(CELL_TYPE_STRING)) {
String value = parser.getText();
try {
System.out.print(" = "
+ new XSSFRichTextString(sst.getEntryAt(Integer
.parseInt(value))));
} catch (NumberFormatException ex) {
System.out.print(" = " + value);
}
} else {
System.out.print(" = " + parser.getText());
}
}
}
parser.close();
sheet2.close();
pkg.close();
}
References
A very good but not too long explanation of SAX and StAX.
http://www.xml.com/pub/a/2003/09/17/stax.html